AB-UPT Technical Review
Introduction:
The final project for my CS7140: Advanced Machine Learning class, I conducted a comprehensive review of the October 2025 paper, AB-UPT: Scaling Neural CFD Surrogates for High-Fidelity Automotive Aerodynamics Simulations via Anchored-Branched Universal Physics Transformers. CFD, or computational fluid dynamics, is the mathematical calculation of fluid dynamic behaviors or practically, a wind tunnel simulation. CFD is relied upon by many critical engineering industries and is extremely expensive in compute, cost, and time. This combination serves as a ripe environment for impactful surrogate model research.
Through 3 novel architectural contributions, AB-UPT sets the standard for both accuracy and inference time, all on a single GPU. My presentation and paper perform a deep-dive into these contributions, enabling broader audiences to understand their underlying methods and impact.

Report
AB-UPT
Code
Figure 1: Full AB-UPT architecture with highlighted core innovations
Multi-Branch Architecture: Decoupling surface, volume, and geometry into three separate branches
Context: CFD inputs
CFD requires a volumetric meshing of the "object in the wind tunnel" to perform its mathematical calculations over. A finite volume meshing algorithm divides the surface of the geometry and the volume of the reference volume into millions of volumetric cells. In short, CFD takes a raw geometry and turns it into a surface mesh and volume mesh. AB-UPT takes advantage of this predefined structure.
AB-UPT's Method: Latent space representation and informational sharing strategy
AB-UPT first generates latent representations of each branch in the encoder before performing cross-attention between the geometry and surface branches and geometry and volume branches to ground the mesh representations in the geometry from which they were derived from.
The Benefits: Mesh independence and direct CAD inference
This enhances the surface and volume branches' representations with the raw 3D geometry's information and decouples the encoder from the rest of the model, meaning, the model is not dependent on the exact mesh orientation of the sample. Furthermore, it enables inference solely with a raw 3D geometry, saving hours of complex mesh algorithm fine-tuning and inference.


Figure 2: Multi-Branch architecture
Figure 3: Anchor attention formulation
Anchor Attention: Solves the attention scaling problem
Context: CFD scale
High-fidelity CFD simulations require extremely fine volumetric meshing. DrivAerML's samples, AB-UPT's industry standard dataset, are comprised of ~140 million cells, which is an intractably large token-space to perform full self-attention with. To put it in context, Llama 3.1's 405B model, it's largest, uses 128,000 tokens.
AB-UPT's Method: Selecting "anchor nodes" from the original mesh to make conditioned predictions
AB-UPT performs a uniform sampling of the initial surface and volume meshes to select "anchor tokens". These anchor tokens cross attend with the remaining "query tokens" and only self-attend to the other anchor tokens. Anchor tokens are responsible for making predictions at their surrounding query tokens' positions.
The Benefits: Significant scale reduction and conditional field output
Anchor attention reduces the O(N^2) problem to an O(MN) problem where M << N (M = anchor tokens, N = query tokens.) This allows dot-product attention to be viable for such an extremely high feature space. A byproduct of this formulation is that the output is now a continuous vector field where the anchor tokens can make predictions at any arbitrary location. This output makes the third core contribution possible.

Equation 1: Divergence-Free formulation
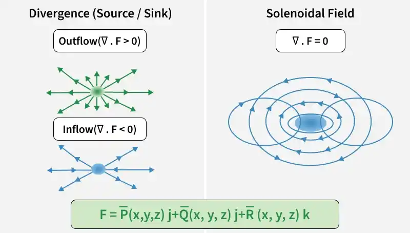
Figure 4: Source, sink, and divergent-free fields
Enforcing Physics : Enforcing real-world outputs
Context: Physics consistency
A fundamental property of incompressible fluids is that they are divergence-free. In other words, there are no sources or sinks in a given volume. CFD enforces this because it computes the strict, physics based, mathematical formulations of fluid behavior. While surrogate models may approach the CFD outputs in accuracy, they are not guaranteed to be physically compliant. The output may not be divergence-free.
AB-UPT's Method: Hard-physics constraint
As a byproduct of anchor-attention, the output is a conditional neural field. This neural field domain is compatible with the divergence-free formulation, shown above. Instead of the model predicting vorticity in a given reference volume, it predicts velocity, and vorticity is calculated directly.
The Benefits: Guaranteed physics consistent outputs
Through the direct divergence-free formulation, AB-UPT's output is guaranteed to be physics consistent. This not only makes AB-UPT the most accurate model, it makes it the only guaranteed physics consistent model as well. This is a requirement for critical engineering industries.